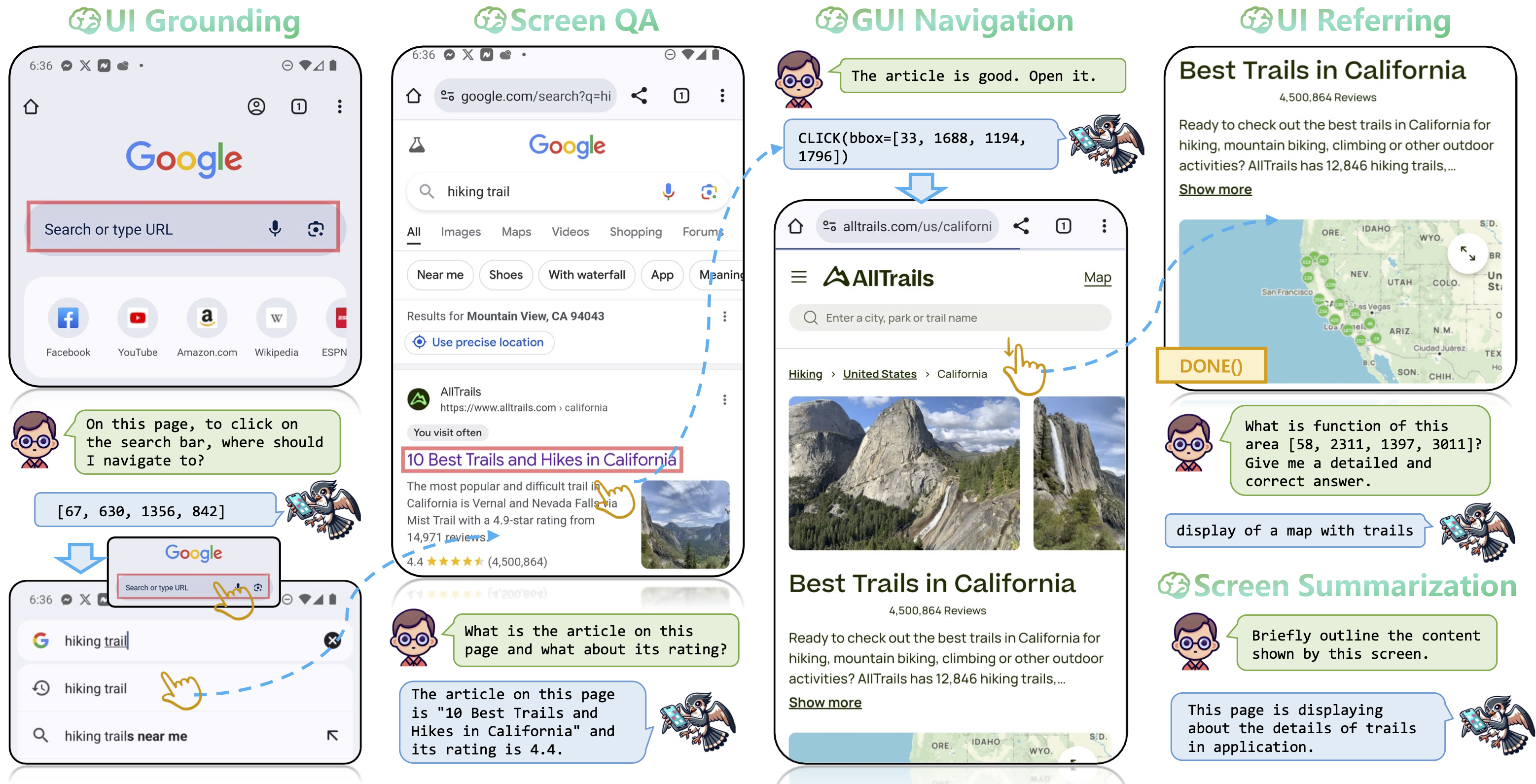
Example of a GUI navigation episode together with the screen understanding tasks supported by UI-Hawk. The user instruction is “I want to use Chrome to discover a new hiking trail.” The bounding boxes predicted by UI-Hawk are represented by red rectangles. The navigation actions are denoted by yellow hands and yellow rectangles.
Graphical User Interface (GUI) agents are expected to precisely operate on the screens of digital devices. Existing GUI agents merely depend on current visual observations and plain-text action history, ignoring the significance of history screens. To mitigate this issue, we propose UI-Hawk, a visual GUI agent specially designed to processing screen streams encountered during GUI navigation. UI-Hawk incorporates a history-aware visual encoder and an efficient resampler to handle the screen sequences. To acquire a better understanding of screen streams, we define four fundamental tasks ---- UI grounding, UI referring, screen question answering, and screen summarization. We develop an automated data curation method to generate the corresponding training data for UI-Hawk. Along with the efforts above, we have also created a benchmark FunUI to quantitatively evaluate the fundamental screen understanding abilities of MLLMs. Extensive experiments on FunUI and GUI navigation benchmarks consistently validate that screen stream understanding is not only beneficial but also essential for GUI navigation.
[UPDATE 2024/08/30] We have our paper online. The benchmark is coming soon!
Given that mobile device screenshots typically have high and variable resolutions, a highly efficient and fine-grained perception capability is crucial for developing effective mobile GUI agents. We develop UI-Hawk to possess such capabilities to handle multiple images of any resolution simultaneously, efficient compression of visual tokens, and precise referring and grounding capabilities, by inheriting a lightweight visual encoder, along with an efficient resampler and a large language model enhanced with LoRA modules and a detection head from TextHawk.
Importantly, UI-Hawk places a strong emphasis on modeling visual history. Historical images often contain valuable details pertinent to ongoing tasks, while most GUI agents rely solely on text-based history, like chain-of-actions (Zhan and Zhang 2023) or chain-of-action-thoughts (Zhang et al. 2024b). UI-Hawk addresses this gap by incorporating images of historical screens as model inputs. Notably, we apply a scalable positional encoding and add textual indicators (e.g., “History Screenshot x”) for each historical screen to explicitly represent the screen streams.
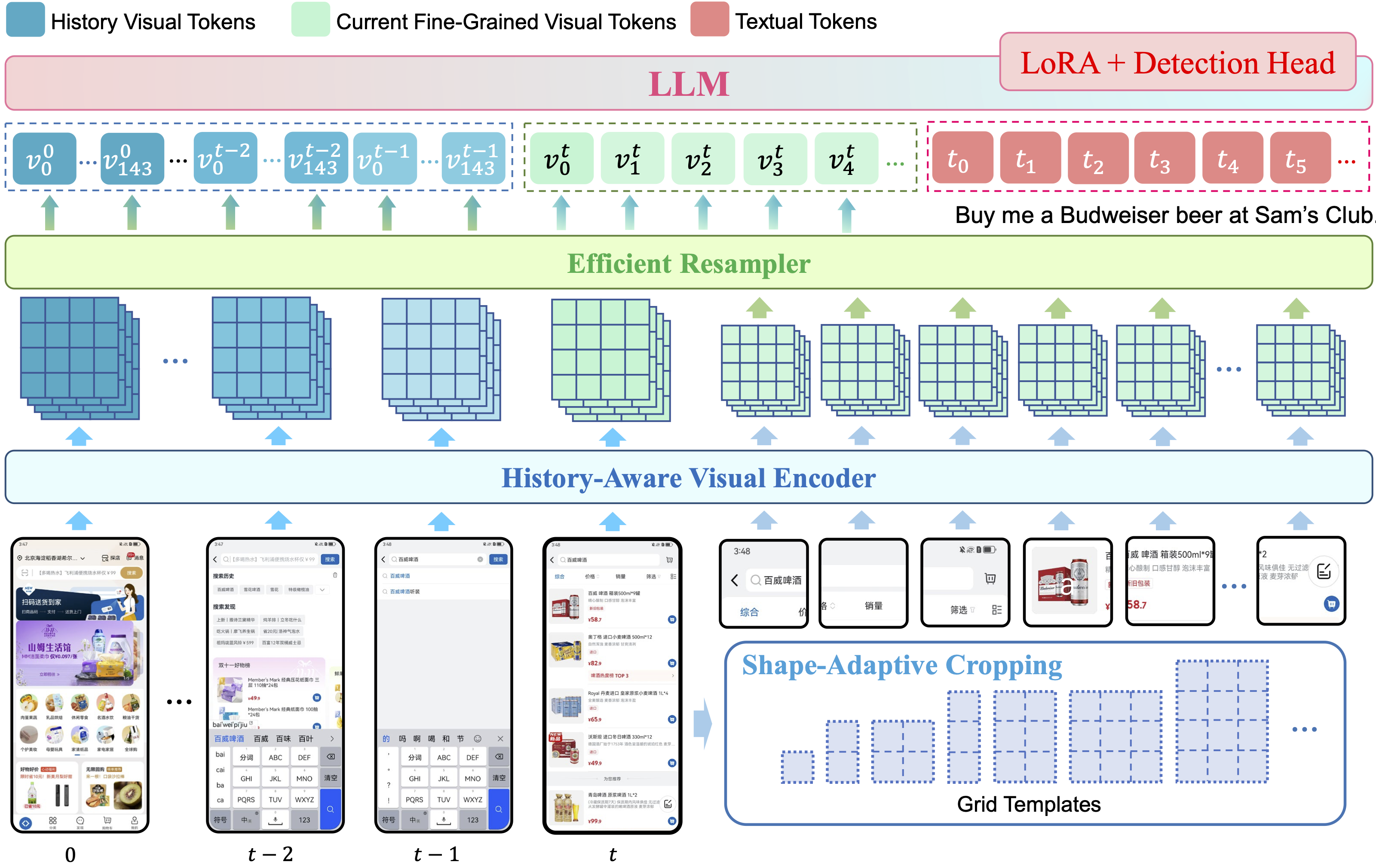
Figure 1: Model architecture of UI-Hawk. The text tokenizer, layer normalization, and skip connections are omitted for simplicity. During the pre-training stage, the visual encoder is trained together with the LLM to obtain the fine-grained perception capabilities. During the fine-tuning stage, the visual encoder is frozen and the LLM is tuned by LoRA.
Given the scarcity of large-scale UI data, we devise an automated data curation method to extract the task-relevant data from diverse screenshots of Chinese and English mobile devices. More details could be found in Section 4 of our paper.
To remedy the blank of comprehensive evaluation data in this area, we introduce FunUI, a bilingual evaluation benchmark encompassing 4 fundamental screen understanding tasks.
Concretely, FunUI distinguishes with previous benchmarks on the following aspects:

Figure 2: Statistics of FunUI Benchmark. (a) Distributions of four fundamental tasks. The deep and shallow color represents for English and Chinese, respectively. (b) Various UI types included. (c) Diverse categories of screen question answering pairs. Note that these categories are not mutually excluded. (d) The annotated answer lengths of screen summarization task.
Table 1 demonstrates the performance of UI-Hawk compared with previous state-of-the-art models on various screen understanding tasks. On English screens, compared to Spotlight and Ferret-UI, UI-Hawk possesses superior results in UI referring and screen question-answering. On Chinese screens, even a minor version of UI-Hawk, UI-Hawk-Minus, sur-passes Qwen-VL and InternVL2 on grounding and referring by a large margin.
Overall, Table 1 suggests that UI-Hawk is a bilingual model with advanced screen understanding capabilities.
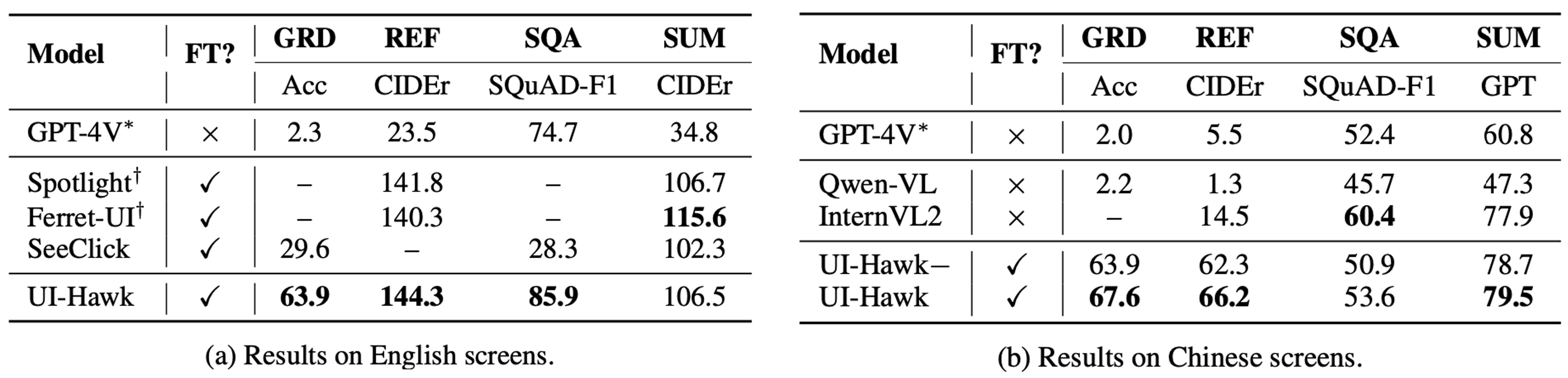
Table 1: Performance of UI understanding on FunUI benchmark. GRD: grounding, REF: referring, SQA: screen question answering, SUM: screen summarization. “FT?” means whether the model is trained on UI-related tasks. *Due to the budget limit, we randomly sampled 500 samples for each task. †Performance of close-source models is from the original paper.
We further validate the sequential navigation capability of UI-Hawk. Table 2 illustrates that UI-Hawk significantly outperforms all other models, achieving a 9% absolute increase in overall action matching score and a 32.5% absolute increase in the prediction accuracy of click operations compared to the most capable OdysseyAgent. Further ablation studies (see our paper) confirm that, the improvements in UI-Hawk are largely attributed to its advanced screen stream understanding ability.

Table 2: Sequential navigation performance on GUI-Odyssey+ dataset. We report the averaged action matching score on six categories of navigation tasks, including tool, information, shopping, media, social and multi-apps, and the overall action matching score. “ClickAcc” stands for the accuracy of click operations, which directly reflects the grounding ability of models.
In this paper, we introduced UI-Hawk, the first GUI agent focused on screen stream understanding. Leveraging the efficient architecture to tackle with screen streams, UI-Hawk excels in four fundamental screen understanding tasks. For a comprehensive assessment under both Chinese and English scenarios, we established the bilingual FunUI benchmark to evaluate the fundamental screen comprehension of MLLMs. Extensive experiments demonstrates that UI-Hawk sets new state-of-the-art performance on episodic GUI navigation tasks, highlighting the importance of robust screen understanding for autonomous GUI agents.
@article{202408.2137,
title = {UI-Hawk: Unleashing the Screen Stream Understanding for GUI Agents},
author = {Jiwen Zhang and Yaqi Yu and Minghui Liao and Wentao Li and Jihao Wu and Zhongyu Wei},
doi = {10.20944/preprints202408.2137.v1},
url = {https://doi.org/10.20944/preprints202408.2137.v1},
year = 2024,
month = {August},
publisher = {Preprints},
journal = {Preprints}
}